I think it's safe to say that nothing in technical interviewing is as controversial as timed coding problems.
When we tell a potential candidate about the content of our interview, no one complains about questions on system design, algorithms and data structures, or what’s going on under the hood when you click a button in your browser.
But timed coding is another matter. We've had candidates outright hang up on the interview call when they realize it involves a coding task (never mind that we tell them ahead of time 🙄), and still more refuse to take the interview in the first place. Maybe 5% of total interviews just don't happen because candidates don't want to do a coding problem. Nor does any other interview section result in me being emailed quite so many manifestos! I've got dozens of the things now, each with their own take on why we shouldn't do timed coding.
We do it anyway.
Why? Because our data tells a pretty clear story: timed coding works.
Timed coding predicts offers really well
We'll start with downstream data.
Any time we refer a candidate to an employer, we track the eventual result: an offer, a rejection, or any number of other outcomes (the company hired someone else, the candidate withdrew, etc). Since we only make a referral after a candidate passes our interview, we can look at how interview data predicts the results of the referral.
If we split candidates up by how far they got on the coding problem, the difference is pretty stark.
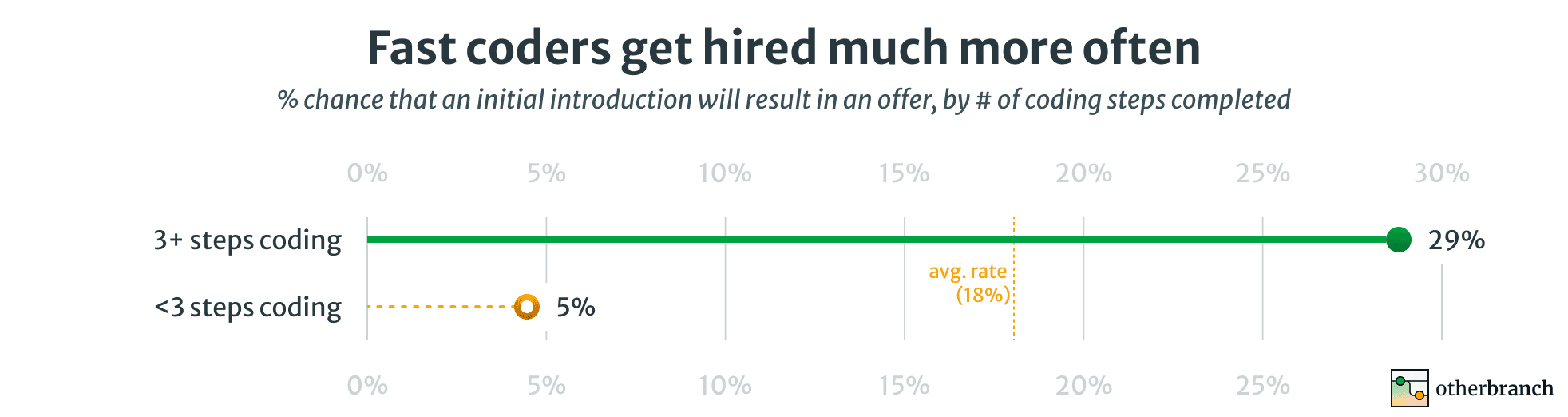
Candidates who complete at least three steps of our coding problem are more than six times as likely to end up with an offer as those who completed two or fewer.
No other section is anywhere near as predictive:
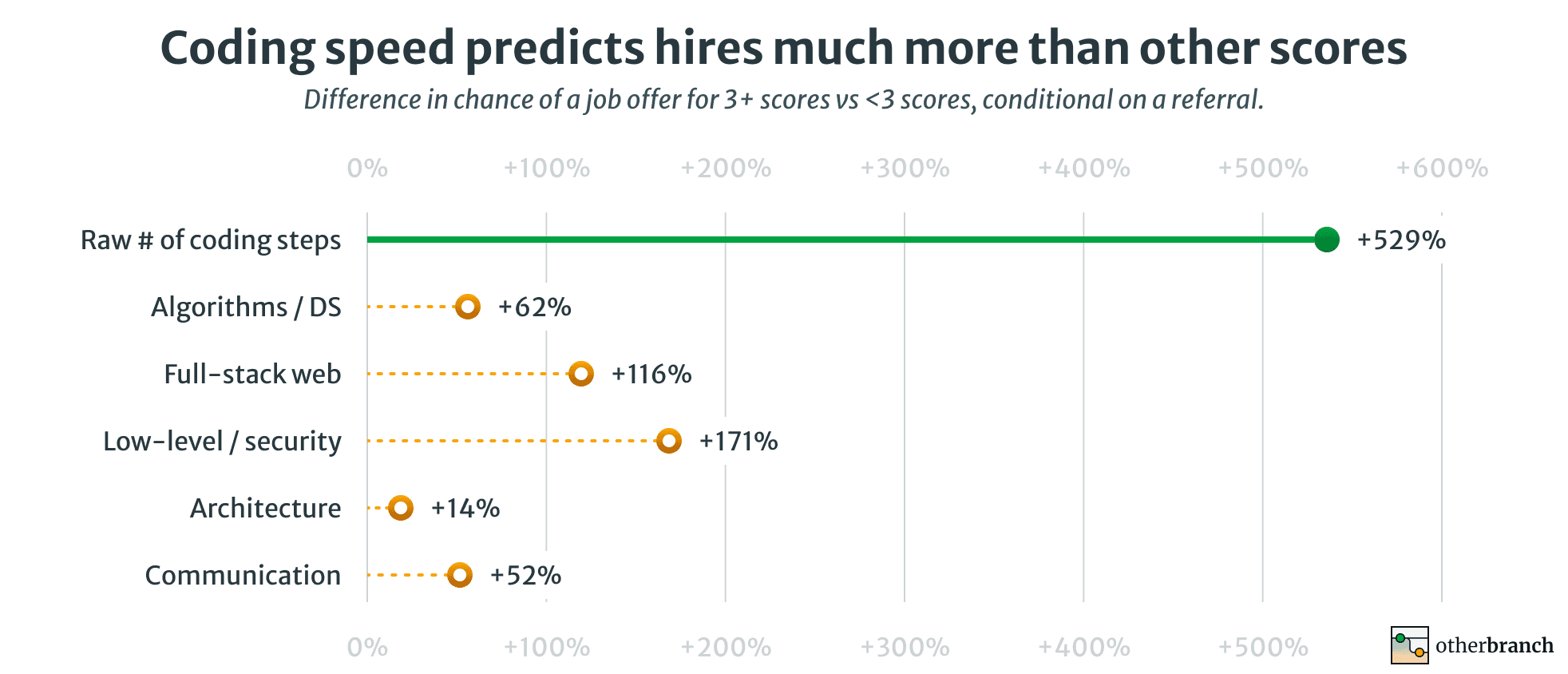
This is a massive effect! Coding is more predictive of downstream outcomes than all other interview sections combined. It's not even close.
Rhetorically, I’d love to just end the post right here. Dramatic graph, nice big numbers, and a conclusion I think is fundamentally true. But we do have to be careful.
Recruiting data is hard
The problem is that data on downstream outcomes doesn't directly tell us how predictive timed coding is. There's a selection bias at work: in order for a candidate to show up in that data set at all, they had to have passed our interview.
Instead, data on downstream effects tells us how much residual effect timed coding has beyond the fact that we made a referral at all.
As an extreme example, imagine that instead of making intelligent pass/fail decisions, we simply referred every candidate. Assuming for the sake of argument that our scores are predictive, you'd expect that:
Most of the candidates we would have failed would have <3 scores.
Most of the candidates we would have failed would not get an offer.
If we were to do an analysis of downstream outcomes with that data, we would find much larger downstream effects from every score even though the actual power of each score has not changed. The only thing that would have changed is that less of the power of each score is being hidden by our selection process, so that it appears in the residual downstream effects instead.
Similarly, in a world where our interview perfectly selected only candidates who would be hired, the downstream predictiveness of every score would be zero. That wouldn't mean that the interview wasn't predictive! Instead, it would mean that all the predictiveness of each score was hidden in the referral, rather than appearing in the residual downstream effects.
The actual statistics are a bit more complicated, but to keep things simple, imagine that:
actual power of coding = residual power of coding + weight of coding in getting a referral
In the pass-everyone-no-questions-asked hypothetical, the last term would be zero, and the residual power would be the actual power:
actual power of coding = residual power of coding + 0
In the perfect interview case, the residual power is zero because all of the power is contained within the referral:
actual power of coding = 0 + weight of coding in getting a referral
In the real world, where our interview is predictive but not perfect, both terms are non-zero, and we have:
actual power of coding = residual power of coding (very large) + ?????
In other words, we can't judge the true power of timed coding without knowing how strongly we weight timed coding in our pass/fail decisions.
The residual data means we can say that timed coding is pretty predictive as a lower bound, but we can't (yet) say whether it's more predictive than other sections. If we were weighting timed coding very weakly (that is, if the unknown term were very small) and we were weighting other sections very heavily (that is, if their corresponding terms were very large), other sections might still have higher overall power than coding despite their weaker residual effects.
I mention all this because it's good to be thorough, and because it provides an excellent example of the difficulty of being data-driven in real-world recruiting.
But as it turns out, it doesn't affect the conclusion at all, because:
We already weight coding heavily
Coding speed is our default tiebreaker in cases where we're not sure whether to make a referral or not, and, purely psychologically, it's the first thing I look at when I'm reviewing an interview scorecard. Going into this analysis, I figured that we probably weighted coding very heavily, perhaps too heavily.
But it's easy to be surprised by your own revealed preferences, so let’s be a bit more rigorous about it.
I pulled every interview we’ve ever done, excluding a few that we did for external clients and test runs (since they’re a different population from the downstream data), and ran a multiple regression with the scores as inputs and our final judgment as an output.
The resulting regression coefficients tell us how much effect each score has on our final judgment, controlling for correlations between the scores. The higher the coefficient, the more heavily we’re weighting that score in deciding whether to refer a candidate, (e.g. a coefficient of 0.3 means that +1 score in that area would move a candidate 30% of the way from, say, a weak fail to a weak pass).
The error bars are pretty wide, but coding ties for the highest weight of any section:
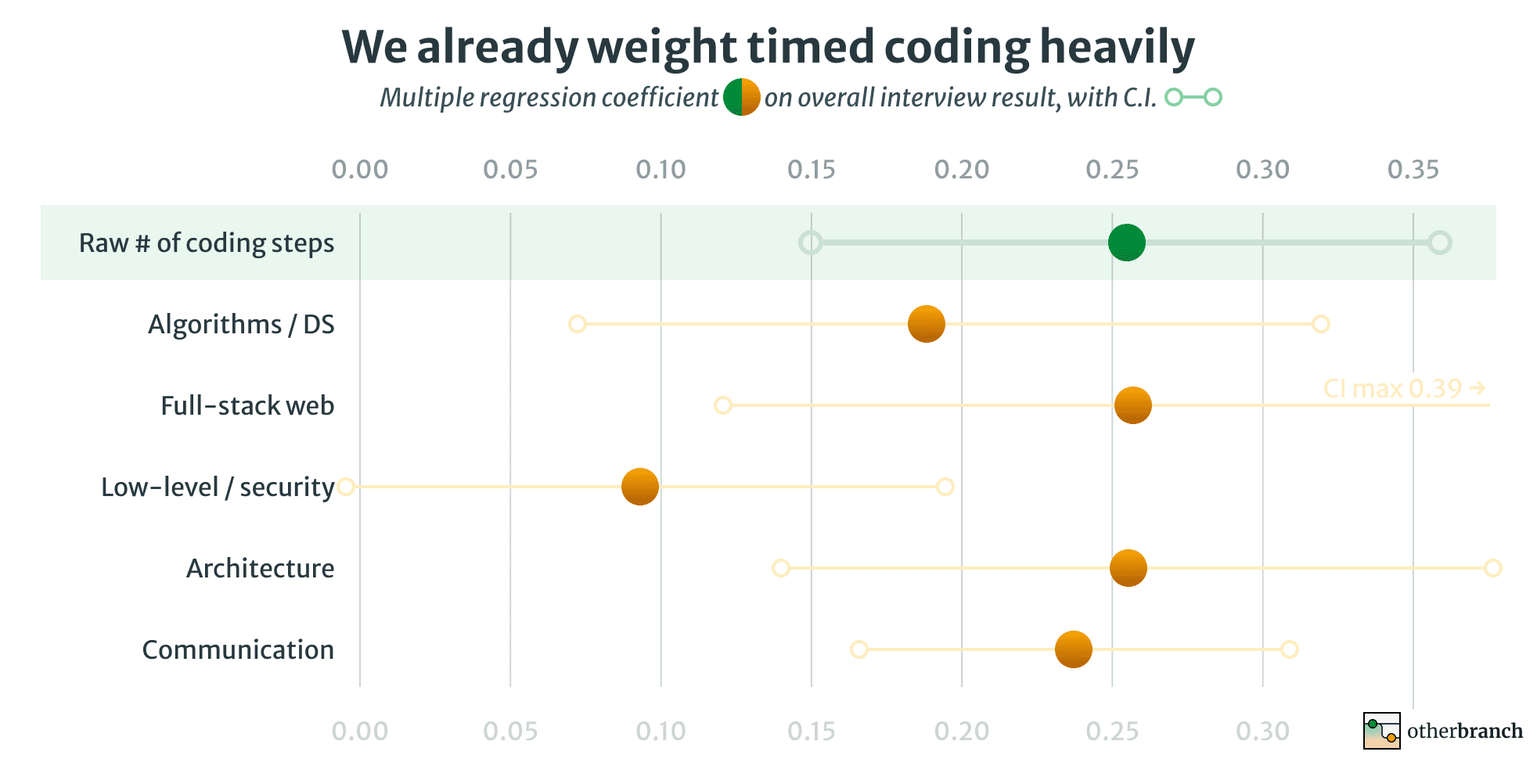
Much like the downstream data set, this doesn’t prove much by itself. All it really tells you is that we think that coding is important when we make our pass/fail judgements, which of course does not mean that it actually is. Actual predictiveness does not appear in this chart at all.
But the combination of our weights with downstream outcomes is another matter.
Our weights say that we're already filtering strongly on timed coding. The downstream outcomes say that even despite that, we are still leaving quite a bit of signal on the table. That's not true for any other interview score: all the others either have a low pass/fail weight (low-level/security) or weak residual predictiveness (architecture, communication).
In other words:
actual power of coding = residual power of coding + weight on coding in getting a referral
actual power of coding = very large + largeactual power of coding = even larger
The combined conclusion is that we should be (uniquely) placing a very high weight on timed coding, moreso than any other interview score. Timed coding is not just as effective as, but significantly more effective than, other interview components at predicting hires.
The usual bias claims don't appear in our data
I think, at this point, we’ve established the statistical validity of timed coding as a measure (at least within the limitations of our data set).
But there is another class of objections to timed coding: that whatever its pragmatic statistical validity, it’s exclusionary or discriminatory. The usual claims center around anxious candidates, usually with the claim that tightly timeboxed coding is a high-stress environment that worsens anxiety. That claim, in turn, is sometimes extended to women as a class, the theory being that female candidates tend to be more anxious interviewees and therefore more susceptible to this effect.
Both claims seem at least plausible to me, and I do want to take them seriously (I believe in this kind of thing a lot more than most Bay Area leadership). But our data set has no evidence of gender or anxiety bias in timed coding.
We collect self-identified gender on signup in order to refer to candidates as they'd prefer, so we can check coding results against that. Candidates who entered female or non-binary/other/complicated on signup actually tended to perform slightly better on the coding problem than their male counterparts, but the resulting gaps are statistically-insignificant.

Anxiety is harder to measure, but interviewers have a number of flags they can use to indicate a candidate’s general personality impressions during an interview. (We don’t score on these in any way, they’re just for this kind of data analysis.) I grouped these flags into anxiety/nervousness-related and arrogance/overconfidence/bluster-related (ignoring any other flags), and split candidates up by which flags they'd gotten if any.
This is by no means a perfect measure, but it's at least data we can look at. And, again, it shows a non-significant difference in favor of anxious candidates:
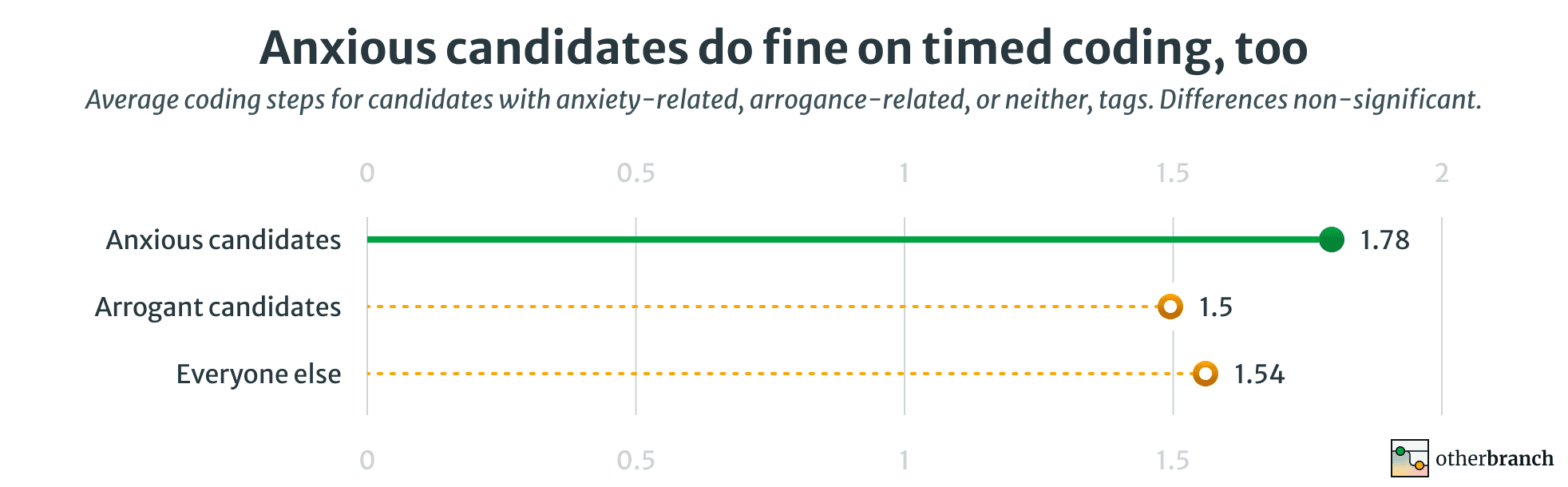
If you prefer your data in anecdote form, the current record-holder on our coding problem is an extremely anxious (cisgender) woman. I had to reassure her like six times to get her to book the call, only for her to score a strong pass on every section but one.
I could speculate on the reasons for the slightly favorable results for anxious candidates. Maybe a coding problem provides clearly-defined parameters rather than having to play emotional-signaling games, or maybe anxious candidates are self-selecting out before interviewing (indeed, some definitely are) in a way that biases the population upward. But I would just be speculating, and given that the gaps are non-significant, it's likely enough that they're just noise.
Nothing in this data suggests a problem to me. Absence of evidence is not proof of absence, but any biases in our coding problem would have to be doing a pretty good job of hiding.
Conclusions
Being empirical is still hard. There are always alternative explanations in real-world data sets, and any real-world data set (including ours) is riddled with invisible biases.
You could try to plead your way out of the obvious conclusion, and I’m not certain you’d be wrong.
But when I see a strong effect size, conserved across different companies and different processes, matching previous data sets I’ve looked at, and with direct and powerful pragmatic implications for how I should be doing my job…well, I know what bet I’m taking.
If you think there’s a cohort of really-skilled-but-bad-at-timed-coding engineers out there, I encourage you to figure out how to identify it. Seriously, send me an email and I’ll happily give you advice on starting your own recruiting company. I care about finding opportunity for people who lack it, and I'll celebrate new innovations in that area even if they aren't mine.
But until you can find those hypothetical engineers, and until you can generate some data that says you’re producing good downstream outcomes, I’d encourage you to consider the obvious conclusion: that timed coding just works.
Our data says so, and other data sets I’ve seen - and I have been in this field for a while - say so too.

